
Read the contents of a worksheet with C#
20 Oct 2009When working with Excel workbooks with C#, I often need to retrieve the entire contents of a particular worksheet, so that I can process the data within C# code. By “the entire contents”, I mean the content of every cell between cell A1 and the last cell of the sheet, that is, the cell such that there is no cell on its right or below it that contains anything.
To do this, I use the following code, where excelWorksheet is a Worksheet (duh):
Excel.Range firstCell = excelWorksheet.get_Range("A1", Type.Missing);
Excel.Range lastCell = excelWorksheet.Cells.SpecialCells(Excel.XlCellType.xlCellTypeLastCell, Type.Missing);
object[,] cellValues;
object[,] cellFormulas;
Excel.Range worksheetCells = excelWorksheet.get_Range(firstCell, lastCell);
cellValues = worksheetCells.Value2 as object[,];
cellFormulas = worksheetCells.Formula as object[,];
The 2 resulting arrays of objects, cellValues and cellFormulas, contain the values and formulas, or null if the cell has no content.
However, while I was working on Akin recently, I realized 2 interesting things I had never noted before. First, the resulting array is 1-based, even though “C# arrays are zero indexed; that is, the array indexes start at zero”. Then, this code will fail if your spreadsheet contains only one value, in cell A1.
To prove my point, here is a snapshot of a QuickWatch of the cellValues array, reading a small spreadsheet. As you can see, the indexing begins at indexes 1 and 1.
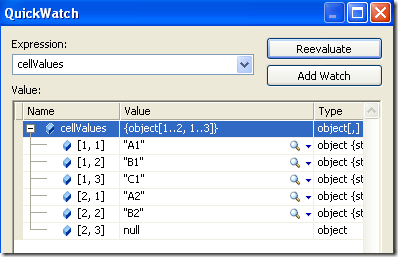
It isn’t especially difficult to handle, but it really came as a surprise to me. Once you got used to zero-based indexes, which are pretty much the norm in .NET, this really is an intriguing oddity.
Once I realized this, I based all my code on the assumption that the array was going to be one-based, and everything went fine, until I realized that the following line was throwing an exception when the worksheet contained only a single populated cell in A1:
cellValues = worksheetCells.Value2 as object[,];
If you want to keep the same code, returning a 2-dimensional array, you have to handle that special case slightly differently, along the lines of:
if (lastCell.Row == 1 && lastCell.Column == 1)
{
cellValues = new object[1,1];
cellFormulas = new object[1,1];
cellValues[0, 0] = firstCell.Value2;
cellFormulas[0, 0] = firstCell.Formula;
}
But now this creates its own particular problem, because cellValues and cellFormulas are of course 0-based. I looked around and couldn’t find a way to declare a one-based array in C# (does anyone know if this is feasible?), so your best options are to either transform the array obtained in the standard case into a 0-based array, or, much less elegant, read the “special case” into a 0-based array which can be read through as a 1-based array:
if (lastCell.Row == 1 && lastCell.Column == 1)
{
cellValues = new object[2,2];
cellFormulas = new object[2,2];
cellValues[1, 1] = firstCell.Value2;
cellFormulas[1, 1] = firstCell.Formula;
}
I am frankly a bit torn between the 2 approaches. On the one hand, I feel much more comfortable working with a standard, 0-based array. On the other hand, while I strongly dislike having a method which returns sometimes a non-standard 1-based array, and sometimes a 0-based array but should be handled as a 1-based array (just describing this makes me queasy), it seems counter-productive to incur the cost of transforming a larger array most of the times, for the sake of the one-cell case, which is clearly an unusual boundary case. I’ll let you decide how you want to handle this!