
Mutant Excel and .Net with ExcelDNA
07 Jun 2010Some time ago, I came across ExcelDNA, an open-source library designed to integrate .Net into Excel, via a post by the Grumpy One, who described it as an interesting way to get Excel to talk to a compiled library. Sounds right down my alley, but I still managed to let 6 months pass until I finally tried it.
This reminded me of another post, by J-Walk this time, where he uses a random walk simulation in VBA to benchmark system performance. Back then, I ran the VBA code, and also the equivalent C# in a console app, out of curiosity: 11.38 seconds, vs. 2.73 seconds. Why not try the same experiment, and see if we can get the best of both worlds and bring some of the C# power into Excel via ExcelDNA?
So I created a Class Library, with the following method, a close equivalent to the VBA benchmark code:
public class Experiment
{
public static string RandomWalk()
{
var stopwatch = new Stopwatch();
stopwatch.Start();
var position = 0;
var random = new Random();
for (var run = 0; run < 100000000; run++)
{
if (random.Next(0, 2) == 0)
{
position++;
}
else
{
position--;
}
}
stopwatch.Stop();
var elapsed = (double)stopwatch.ElapsedMilliseconds / 1000d;
return "Position: " + position.ToString() + ", Time: " + elapsed.ToString();
}
}
The ExcelDNA tutorial is completely straightforward: compile the dll, drop it to a folder with a copy of the xll stub and the dna text file, add a reference to the add-in in Excel, and that’s it – your .Net function is now available from Excel. If what you are used to is VSTO, at that point your jaw is dropping, and you are staring in disbelief.
I then added the following macro, timing the entire call to make sure the overhead was taken into account in comparing the VBA and DNA code:
Sub DnaTimer()
Dim StartTime As Single
StartTime = Timer
dnaResult = Application.Run("RandomWalk")
MsgBox dnaResult & " - " & Timer - StartTime & " seconds"
End Sub
Here are the results on my Intel Core 2 Duo 1.80 GHz laptop, with 4 GB Ram.
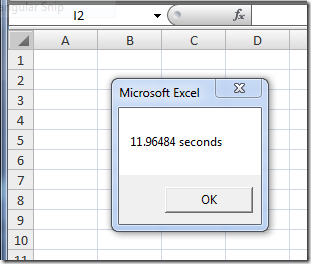
VBA: 11.96 seconds.
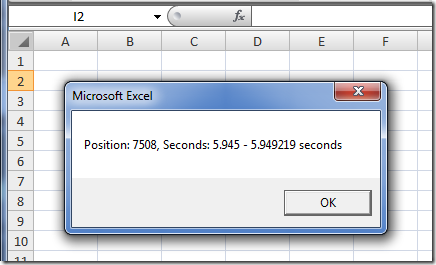
DNA: 5.95 seconds, with negligible overhead.
John Walkenbach published the performance distribution of the results reported by his readers; my laptop ranks slightly below the median. In under half an hour, including reading the tutorial, I wrote a user-defined function that was the second fastest of the pack, using a fairly average laptop.
Would I expect this type of result in every situation? No. This example is probably as good as it can get for ExcelDNA, with no interaction with the Excel object model, and mostly computation. I am definitely going to keep playing with ExcelDNA, to see how it fares in other less obviously advantageous situations; but it certainly seems like a great option when you need a few computation-heavy functions, without the overhead of VSTO.
Now for some nitpicking: one thing I’d like to see is support for .Net 4.0. I am probably biased by my recent experiments with the Task Parallel Library, but it seems to me that ExcelDNA is a great fit when the goal is to extend Excel with heavy algorithms in .Net – and the TPL is just great for writing parallel code that leverages multi cores, without having to worry much about managing threads. It could be done without it, but it certainly is way easier using it (I am hearing that there would be some unsupported way to use some of the Parallel Extensions via Reactive Extensions in .Net 3.5; if I get this to work, I’ll post about it later).
I specifically wanted to use parallelism here because of a comment by John Walkenbach, asking whether it is possible to run this under 1 second. Given the results he posted, I doubt it’s feasible in VBA; however, this may be possible using parallelism in .Net – I think it’s a fun challenge, but I am too lazy to try that out without the TPL! Maybe some other person will step up to the plate?