
AdaBoost in F#
29 Dec 2012Machine Learning in Action, in F#
Porting Machine Learning in Action from Python to F#
- KNN classification (1)
- KNN classification (2)
- Decision Tree classification
- Naive Bayes classification
- Logistic Regression classification
- SVM classification (1)
- SVM classification (2)
- AdaBoost classification
- K-Means clustering
- SVD
- Recommendation engine
- Code on GitHub
This post continues my journey converting the Python samples from Machine Learning in Action into F#. On the program today: chapter 7, dedicated to AdaBoost. This is also the last chapter revolving around classification. After almost 6 months spending my week-ends on classifiers, I am rather glad to change gears a bit!
The idea behind the algorithm
Algorithm outline
AdaBoost is short for “Adaptative Boosting”. Boosting is based on a very common-sense idea: instead of trying to find one perfect classifier that fits the dataset, the algorithm will train a sequence of classifiers, and, at each step, will analyze the latest classifiers’ results, and focus the next training round on reducing classification mistakes, by giving a bigger weight to the misclassified observations. In other words, “get better by working on your weaknesses”.
The second idea in AdaBoost, which I found very interesting and somewhat counter-intuitive, is that multiple poor classification models taken together can constitute a highly reliable source. Rather than discarding previous classifiers, AdaBoost combines them all into a meta-classifier. AdaBoost computes a weight Alpha for each of the “weak classifiers”, based on the proportion of examples properly classified, and classifies observations by taking a majority vote among the weak classifiers, weighted by their Alpha coefficients. In other words, “decide based on all sources of information, but take into account how reliable each source is”.
In pseudo-code, the algorithm looks like this:
Given examples = observations + labels,
Start with equal weight for each example.
Until overall quality is good enough or iteration limit reached,
From the available weak classifiers,
Pick the classifier with the lowest weighted prediction error,
Compute its Alpha weight based on prediction quality,
Update weights assigned to each example, based on Alpha and whether example was properly classified or not
The weights update mechanism
Let’s dive into the update mechanism for both the training example weights and the weak classifiers Alpha weights. Suppose that we have
- a training set with 4 examples & their label [ (E1, 1); (E2, - 1); (E3, 1); (E4, - 1) ],
- currently weighted [ 20%; 20%; 30%; 30% ], (note: example weights must sum to 100%)
- f is the best weak classifier selected.
If we apply a weak classifier f to the training set, we can check what examples are mis-classified, and compute the weighted error, i.e. the weighted proportion of mis-classifications:
| Example | Label | Weight | f(E) | f is… | weighted error |
|---|---|---|---|---|---|
| E1 | 1 | 0.2 | 1 | correct | 0.0 |
| E2 | -1 | 0.2 | 1 | incorrect | 0.2 |
| E3 | 1 | 0.3 | 1 | correct | 0.0 |
| E4 | -1 | 0.3 | -1 | correct | 0.0 |
| 0.2 |
This gives us a weighted error rate of 20% for f, given the weights.
The weight given to f in the final classifier is given by
Alpha = 0.5 x ln ((1 - error) / error)
Here is how Alpha looks, plotted as a function of the proportion correctly classified (i.e. 1 - error):
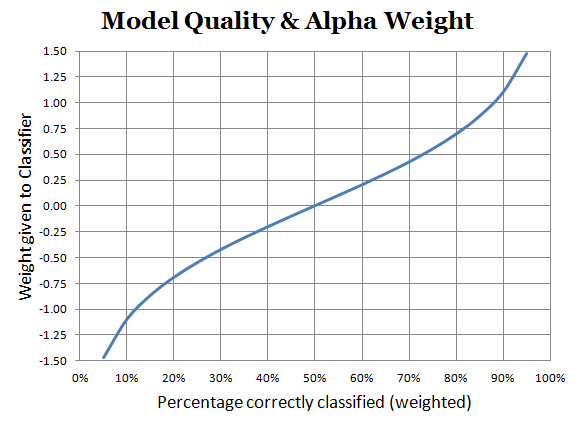
If 50% of the examples are properly classified, the classifier is totally random, and gets a weight of 0 - its output is ignored. Higher quality models get higher weights - and models with high level of misclassification get a strong negative weight. This is interesting; in essence, this treats them as a great negative source of information: if you know that I am always wrong, my answers are still highly informative - you just need to flip the answer…
The weights given to each training example are updated according to the following formula:
new weight = old weight x exp (-Alpha)for correct predictions,new weight = old weight x exp (Alpha)for incorrect predictions,renormalize all weights to sum up to 100%
In graphical form, here is what happens to the training sample weights, as a function of the weak classifier quality:
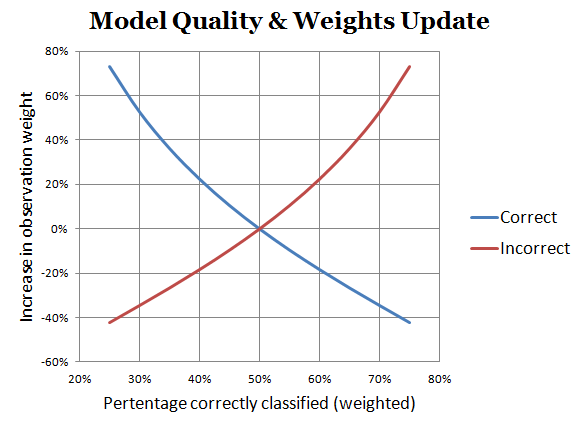
For a totally uninformative classifier (50% correctly classified), no change happens. A classifier with 70% hit rate will boost each misclassified example by about 50%, and decrease the weight of properly classified ones by about 35%. In other words, if you have an excellent classifier already, go ahead and make the next round hard, by focusing heavily on misclassified examples. If the current classifier is mediocre, just apply a moderate change to the weights.
Decision Stumps
I mentioned earlier that AdaBoost combined “weak classifiers” into a “strong classifier”. The version we’ll implement below uses decision stumps, which definitely qualifies as weak. A decision stump is a single-node decision tree: it considers a single feature at a time, and classifies based on that feature alone. A stump with a continuous variable will for instance classify as a 1 anything above a threshold value, and a - 1 everything else.
Note that nothing would prevent us from using more complex classifiers in AdaBoost - the beauty of using stumps is that first, they are very easy to evaluate, and then, they prove the point that one can indeed use terrible classifiers to produce a good overall classifier.
F# implementation
Enough talking, let’s dive into the F# implementation. The code discussed below is available on GitHub, and is located in the AdaBoost.fs file, which can be browsed here.
We’ll start by defining two Record types:
// A "known example": an observation and its known class label
type Example = { Observation: float []; Label: float }
// A "weak learner": a rudimentary classifier and its weight Alpha
type WeakLearner = { Alpha: float; Classifier: float [] -> float }
An Example represents an observation from the training dataset, with its features, represented as an array of floats, and its Label, a float which is expected to be either 1.0 or -1.0. A Weak Learner is one of the classifiers identified by the AdaBoost procedure: it has a weight Alpha, and a Classifier, a function which, given an observation (an array of floats), will return a Label, expected to be -1.0 or 1.0.
Next, we define the stumpClassify function:
// "Stump": classify based on whether value of a single feature
// is greater/lower than threshold.
let stumpClassify dimension threshold op (observation: float []) =
if op observation.[dimension] threshold then 1.0 else -1.0
stumpClassify takes in a dimension (the index of the feature), a threshold, an op-erator, and returns 1.0 or -1.0 depending on the value of the feature for that dimension, for the supplied observation.
The unit tests suite illustrates the usage of stumpClassify:
[<Test>]
member this.``stumpClassify verification`` () =
let obs = [| 1.0; 2.0 |]
// obs.[0] = 1.0 is >= 2.0
stumpClassify 0 2.0 (>=) obs |> should equal -1.0
// obs.[0] = 1.0 is not >= 1.0
stumpClassify 0 1.0 (>=) obs |> should equal 1.0
// obs.[1] = 2.0 is <= 3.0
stumpClassify 1 3.0 (<=) obs |> should equal 1.0
// obs.[1] = 2.0 is not <= 1.0
stumpClassify 1 1.0 (<=) obs |> should equal -1.0
In the first case, we pass dimension 0, a threshold of 2.0, and the operator >=. The value of obs at index 0 is 1.0, which is not >= 2.0, so the stump should classify that observation as a - 1.0, a negative.
Next, we define a weightedError utility function:
let weightedError (ex: Example) weight classifier =
if classifier(ex.Observation) = ex.Label then 0.0 else weight
It simply takes a training example, a weight and a classifier. If the example is properly classified, it returns a 0.0 (no error), otherwise it returns the weight.
We are now armed to generate and select the best stump classifier, given a training set and a set of weights for each of the training examples:
// Generate stump classifiers for each feature, varying the
// threshold and the comparison, and pick the stump that
// has the lowest weighted error.
let bestStump (sample: Example []) weights numSteps =
seq {
let dimensions = sample.[0].Observation.Length
for dim in 0 .. dimensions - 1 do
let column = sample |> Array.map(fun obs -> obs.Observation.[dim])
let min, max = Array.min column, Array.max column
let stepSize = (max - min) / numSteps
for threshold in min .. stepSize .. max do
for op in [ (<=); (>=) ] do
let stump = stumpClassify dim threshold op
let error =
Seq.map2 (fun example weight ->
weightedError example weight stump) sample weights
|> Seq.sum
yield stump, error }
|> Seq.minBy (fun (stump, err) -> err)
Our goal here is to select from multiple stump candidates the one with the lowest error rate. We generate all stumps in a Sequence: we iterate over every single feature / dimension, generate multiple thresholds between the min and max value for the feature, and iterate over two possible ops, less than and greater than comparison. For each case, we create a stump function, using partial application: because the dimension, threshold and op are set, its signature is
(float [] - > float),
which qualifies it as a Classifier. We can now map each Example in the sample to weightedError, yield each stump and its weighted error as a tuple - and extract the tuple with lowest error from that sequence.
We are now done with the first half of the pseudo-code loop we presented earlier. Now we need to tackle the computation of the Alpha weight, and the update of the observation weight.
Let’s start with 2 auxiliary functions:
// Classify an observation using a list of weak learners
// and their weight Alpha: compute the alpha-weighted sum
// of the predictions of each learner, and decide based on sign.
let classify model observation =
let aggregate = List.sumBy (fun weakLearner ->
weakLearner.Alpha * weakLearner.Classifier observation) model
match aggregate > 0.0 with
| true -> 1.0
| false -> -1.0
// Compute proportion of Examples (sample) properly classified
// using a model (a list of alpha-weighted weak learners)
let aggregateError sample model =
Seq.averageBy (fun obs ->
if (classify model obs.Observation = obs.Label) then 0.0 else 1.0) sample
The expected output of the AdaBoost training - the “model” - is a list of Weak Learners, a list of Classifiers with an Alpha weight. Given such a model, the meta-model will decide how to classify an Observation by taking a majority vote among the Weak Learners, weighted by their respective Alphas. classify does just that: it sums the verdict of each Weak Learner, and decides based on the sign of the result. aggregateError simply applies the model to a sample, to compute the error rate of the classifier, the proportion of mis-classified Examples.
It’s time for the final fireworks - let’s put it all together into the training function:
// Train the classifier on the data, using Decision Stumps,
// (http://en.wikipedia.org/wiki/Decision_stump)
// iterations is the maximum iterations, numSteps the "granularity"
// of the threshold search (ex. 10.0 = 10 values between min and max),
// and targetError the desired error percentage of the classifier.
let train dataset labels iterations numSteps targetError =
// Prepare data
let sample = Array.map2 (fun obs lbl ->
{ Observation = obs; Label = lbl } ) dataset labels
// Recursively create new stumps and observation weights
let rec update iter stumps weights =
// Create best classifier given current weights
let stump, err = bestStump sample weights numSteps
let alpha = 0.5 * log ((1.0 - err) / err)
let learner = { Alpha = alpha; Classifier = stump }
// Update weights based on new classifier performance
let weights' =
Array.map2 (fun obs weight ->
match stump(obs.Observation) = obs.Label with
| true -> weight * exp (-alpha)
| false -> weight * exp alpha) sample weights
|> normalize
// Append new stump to the stumps list
let stumps' = learner :: stumps
// Search termination
match iter >= iterations with
| true -> stumps' // done, we passed iterations limit
| false ->
// compute aggregate error
let error = aggregateError sample stumps'
match error <= targetError with
| true -> stumps' // done, we reached error target
| false -> update (iter + 1) stumps' weights'
// Initiate recursive update and create classifier from stumps
let size = Array.length dataset
let weights = [| for i in 1 .. size -> 1.0 / (float)size |]
let model = update 0 [] weights // run recursive search
classify model // the Classifier function
We pass in a dataset and labels (an array of observations, and an array of 1.0 or - 1.0), a maximum number of iterations, numSteps (defining the granularity of the threshold search), and a targetError, the classification error proportion we consider good enough.
We transform the dataset and labels into a single array of Examples, and create a recursive update function, which expects the current iteration number, a list of WeakLearners and their weight Alpha, and the current weights applied to each example, modeled as an array of floats. Note that we don’t need to pass in the sample: it will never change during the process, so we use it via closure.
Each step of the recursion simply picks the best stump, computes its Alpha weight and creates the corresponding WeakLearner. We can now create an updated Weights vector, by checking whether or not our stump correctly classified each example, and re-normalizing the result.
Finally, we append the new stump to our list of stumps, and check whether we are done (iteration limit reached, or current aggregate error is good enough) or need to continue.
We initialize the weights to be equal for each Example in the sample, launch the recursive update - and once we are done, we “return” the classify function defined earlier, using partial application to pass in the current list of stumps, so that the final result has signature (float [] - > float), a ready-to use classifier. And… we are done.
An example: wine classification
To see the algorithm in action, we’ll try it out on another of the UC Irvine Machine Learning dataset, the Wine dataset. It’s a small dataset, containing 178 Italian wines coming from the same region, made of three different grape varieties, or “cultivars” (the labels) - and measured across 13 chemicals (the features).
The full example is on GitHub, in the script file Chapter7.fsx, which you can browse here.
The gist of it is similar to the script Chapter6-digits.fsx we discussed last time. We create a WebRequest to grab the data from UCI, and parse it into the right format, breaking each row of comma-separated data into a integer label (the first element), and an array of floats (the 13 features).
What goes on between lines 50 and 73 is a bit ugly. Once the dataset is read, we need to separate it into 2 equally sized parts: a training set, and a validation set, which we will use to evaluate how our classifier is doing. Because the original dataset is ordered by label, we cannot simply take the first half of the dataset. Instead, we separate the dataset by label, take 50% of each, and recombine them.
Anyways, once the gory data preparation is over, training and evaluating the classifier is a breeze:
let wineClassifier = train trainingSet trainingLabels 20 10.0 0.01
// Performance on training set
Array.zip trainingSet trainingLabels
|> Array.averageBy (fun (obs, lbl) -> if (wineClassifier obs) = lbl then 1.0 else 0.0)
|> printfn "Proportion correctly classified: %f"
// Performance on validation set
validation
|> Array.averageBy (fun (obs, lbl) -> if (wineClassifier obs) = lbl then 1.0 else 0.0)
|> printfn "Proportion correctly classified: %f"
Running this on my machine produces the following:
Proportion correctly classified: 1.000000
Proportion correctly classified: 0.784091
Real: 00:00:00.050, CPU: 00:00:00.046, GC gen0: 1, gen1: 0, gen2: 0
Training seems to go well (100% properly classified), and we end up with close to 80% correct calls on the validation set. Not bad!
Comments & Conclusion
A few comments before closing. First, there are some obvious ways the code could be optimized. For instance, there is no reason to re-generate the stumps in bestStump every time - they could be generated only once, only the best candidate selection given the current weights need to happen in every step. It’s also not necessary to re-compute the aggregate error from scratch every time, maintaining a running total would do the job. I am sure there are other spots that could be improved - I focused primarily on making the algorithm understandable, and performance looked good enough that I didn’t think it worth investigating further.
One thing I have been wondering about, but was too lazy to check - in this version of AdaBoost, which follows very closely the book, we are selecting the stump that yields the minimum weighted prediction error. The Wikipedia version actually proposes a different criteria, the stump that maximizes abs (50% - error). The difference is interesting - what this does is search for the “most informative” model possible: a model which is correct all the time when there are two choices is exactly as good as a model which is incorrect all the time. I suspect that this is actually a better criterion, and would allow us to remove one of the two operators ( <= and >=) in our stump selection function.
One idea I have left out for the moment is refactoring a bit the code, to make possible to inject arbitrary classifiers into AdaBoost. It doesn’t look that complicated, but at that point I am reaching saturation point on classifiers, so I’ll leave that for another day!
That’s it for today! Chapter 7 concludes the Part 1 of Machine Learning in Action, dedicated to Classification - a nice timing, as we are also concluding 2012. We’ll move to different topics in 2013, but I will very probably revisit at some point the different classifiers, to see if a clean, common API can be extracted, and also see if there is room for improvement. If you have questions or comments, please let me know!