
Exploring Gradient Boosting
06 Aug 2016I have recently seen the term “gradient boosting” pop up quite a bit, and, as I had no idea what this was about, I got curious. Wikipedia describes Gradient Boosting as
a machine learning technique for regression and classification problems, which produces a prediction model in the form of an ensemble of weak prediction models, typically decision trees.
The page contains both an outline of the algorithm, and some references, so I figured, what better way to understand it than trying a simple implementation. In this post, I’ll start with a hugely simplified version, and will build up progressively over a couple of posts.
I like to work on actual data to understand what is going on; for this series, I will (for no particular reason) use the Wine Quality dataset from the UCI Machine Learning repository. (References: P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.)
In this example,
Two datasets are included, related to red and white vinho verde wine samples, from the north of Portugal. The goal is to model wine quality based on physicochemical tests.
In plain English, we have a bunch of wines, and each of them has chemical measurements on 11 characteristics, and a rating. What we want is to use that data to estimate a model that, based on these measurements, will predict whether or not we should stay away from a particular bottle.
Exploring the dataset
Note: the full script is availabla as a Gist here.
We will use FSharp.Data and XPlot to respectively extract and visualize the dataset, from a raw F# script. Data extraction is straightforward, using the CSV Type Provider:
type Wine = CsvProvider<"data/winequality-red.csv",";",InferRows=1500>
let reds = Wine.Load("data/winequality-red.csv")
Let’s start by creating a couple of type aliases, to clarify the intent of the code:
type Observation = Wine.Row
type Feature = Observation -> float
let ``Alcohol Level`` : Feature =
fun obs -> obs.Alcohol |> float
let ``Volatile Acidity`` : Feature =
fun obs -> obs.``Volatile acidity`` |> float
Here we define each row from the dataset as an Observation, and a Feature as a function that, given an Observation, will return to us a float, a numeric value that describes one aspect of an Observation. We then create 2 features, picking completely arbitrarily 2 measurements, Alcohol Level and Volatile Acidity.
Let’s take a look at whether there is a visible relationship between Alcohol Level and Quality, creating a scatterplot with XPlot:
reds.Rows
|> Seq.map (fun obs -> ``Alcohol Level`` obs, obs.Quality)
|> Chart.Scatter
|> Chart.WithOptions options
|> Chart.WithTitle "Alcohol Level vs. Quality"
|> Chart.WithXTitle "Alcohol Level"
|> Chart.WithYTitle "Quality"
|> Chart.Show
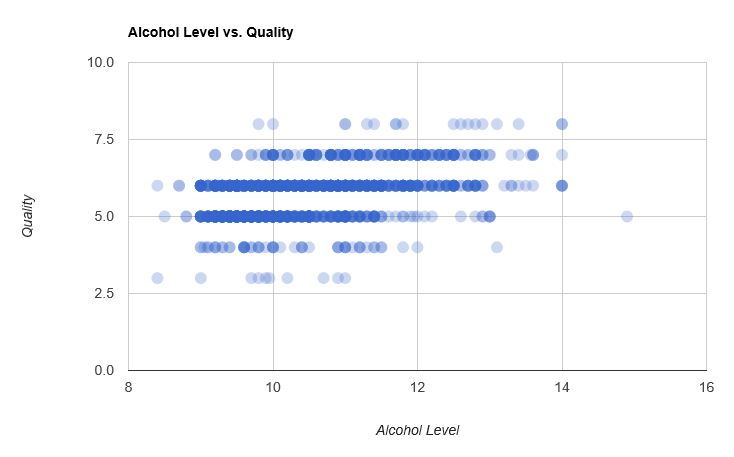
The relationship isn’t clear cut, but higher alcohol levels seem to go together with higher quality. Similarly, we plot Volatile Acidity against Quality:
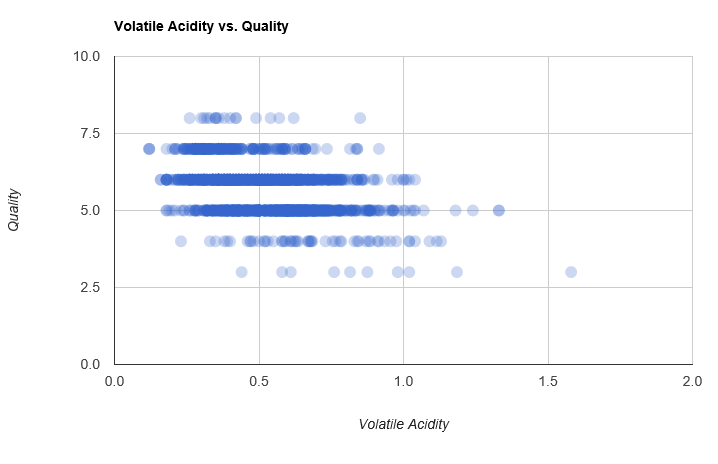
Again, no blatant relationship, but as acidity goes up, quality seems to generally decrease.
In other words, people seem to enjoy more booze and sweetness - this is not unreasonable. What we want next is to use that information, and create a model that uses, say, Alcohol Level to predict Quality, that is, a Regression model. Given how dispersed the data is on our charts, we should not hope for perfect predictions here. On the other hand, there is a bit of a trend visibile, so using that information, we can hope for predictions that are better than random guesses.
Stumps
One of the interesting ideas behind ensemble models (which boosting is an example of) is to try and combine many mediocre prediction models (“weak learners”) into a good one. Here we will start with the weakest model I can think of, namely stumps.
A stump is simply a function that predicts one value if the input is below a given threshold, and another one if the input is above the threshold. As an example, we could create a stump that predicts a certain quality if the Alcohol Level is below, say, 11.0, and another value otherwise.
What predictions should we make? A reasonable solution would be to
- for wines with alcohol below
11.0, predict the average quality observed across wines under11.0alcohol, - for wines with alcohol above
11.0, predict the average quality observed across wines over11.0alcohol.
This is, obviously, a very crude prediction model, but let’s roll with it for now, and implement that approach:
type Example = Observation * float
type Predictor = Observation -> float
let learnStump (sample:Example seq) (feature:Feature) threshold =
let under =
sample
|> Seq.filter (fun (obs,lbl) -> feature obs <= threshold)
|> Seq.averageBy (fun (obs,lbl) -> lbl)
let over =
sample
|> Seq.filter (fun (obs,lbl) -> feature obs > threshold)
|> Seq.averageBy (fun (obs,lbl) -> lbl)
fun obs ->
if (feature obs <= threshold)
then under
else over
We define another couple of types for convenience: an Example is an Observation, together with a float value, the value we are trying to predict, and a Predictor is a function that, given an Observation, will return a prediction (a float).
The learnStump function takes a sample (a collection of Example to learn from), a Feature, and a threshold, computes the average value on both sides of the threshold, and returns a Predictor, a function that, given an observation, will return one of the 2 possible predictions, depending on whether the value for the Feature is under or over the threshold.
Let’s try this out on our data, picking an arbitrary value of 11.0 as a threshold:
let redSample =
reds.Rows
|> Seq.map (fun row -> row, row.Quality |> float)
let testStump = learnStump redSample ``Alcohol Level`` 11.0
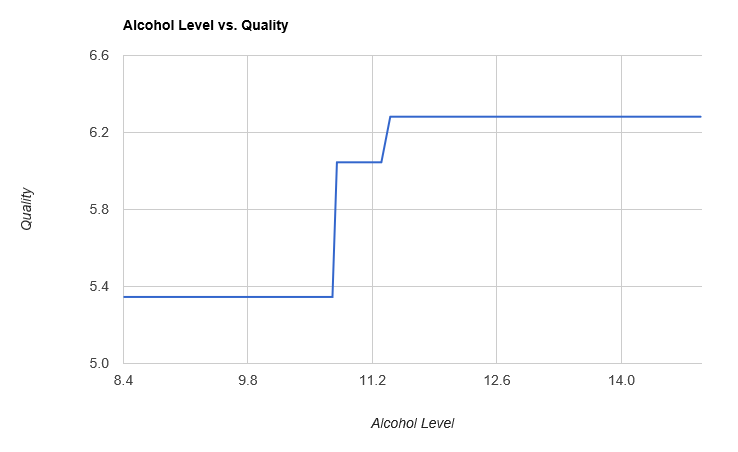
Let’s now visualize our model, by plotting alcohol level against predicted quality:
let predicted =
redSample
|> Seq.map (fun (obs,value) -> (``Alcohol Level`` obs, obs |> testStump))
predicted
|> Seq.sortBy fst
|> Chart.Line
|> Chart.WithTitle "Alcohol Level vs. Quality"
|> Chart.WithXTitle "Alcohol Level"
|> Chart.WithYTitle "Quality"
|> Chart.Show
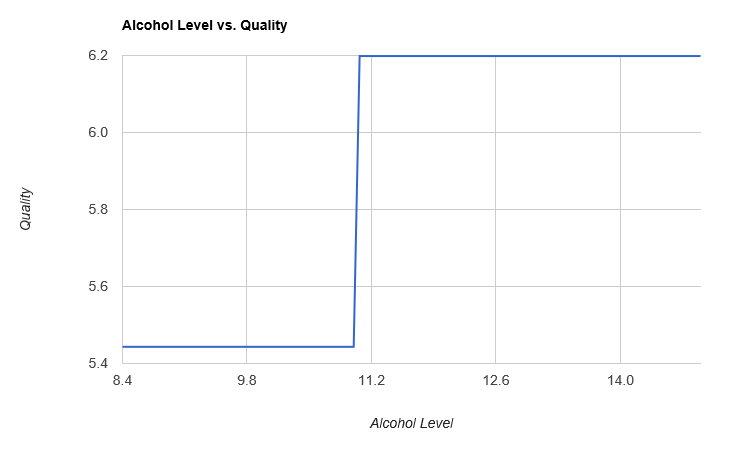
For alcohol levels under 11.0, the model predicts a quality of 5.443, for levels above 11.0, a quality of 6.119.
Picking a good stump
Now we know how to create a stump, based on a sample, a feature, and a threshold. Progress!
We have a new problem on our hands, though. For a specific feature, we have many, many possible stumps. How can we select one? We need a way to compare two stumps (or any Predictor, really). Again we will go for simple: a perfect model would predict the correct response for every single Example we know of. Conversely, a bad model would produce far-off predictions. We will measure the quality by summing together all the prediction errors, squared:
let sumOfSquares (sample:Example seq) predictor =
sample
|> Seq.sumBy (fun (obs,lbl) ->
pown (lbl - predictor obs) 2)
This is not the only approach possible, but this is reasonable. A perfect model would give us 0.0, because every single prediction would equal the value we are trying to predict, and prediction errors in either direction (over or under) will create a positive penalty, because of the square. The lower the sumOfSquares, the closer the predictions are overall to the target.
As a benchmark, our testStump has the following “cost”:
sumOfSquares redSample testStump
val it : float = 868.8435509
868.84 is now the number to beat.
Another question solved, another one to answer: which thresholds should we try? Rather than trying out every single possible value, which could end up being quite painful, we will go again for simple. We will take all the alcohol level values, and divide them between n evenly spaced intervals, like this:
let evenSplits (sample:Example seq) (feature:Feature) (n:int) =
let values = sample |> Seq.map (fst >> feature)
let min = values |> Seq.min
let max = values |> Seq.max
let width = (max-min) / (float (n + 1))
[ min + width .. width .. max - width ]
If we apply this to the alcohol levels, we get the following:
let alcoholSplits = evenSplits redSample ``Alcohol Level`` 10
val alcoholSplits : float list =
[8.990909091; 9.581818182; 10.17272727; 10.76363636; 11.35454545;
11.94545455; 12.53636364; 13.12727273; 13.71818182]
Selecting the best stump at that point is easy: take the splits, for each of them, learn a stump, compute the sumOfSquares, and pick the stump with the lowest value:
let bestStump =
alcoholSplits
|> List.map (learnStump redSample ``Alcohol Level``)
|> List.minBy (sumOfSquares redSample)
How good is it? Let’s check:
sumOfSquares redSample bestStump
val it : float = 864.4309287
This is an improvement over our randomly picked threshold, albeit a small one. For alcohol levels under 10.76, our model predicts 5.392, otherwise 6.091.
Combining Stumps
Now we have a slightly less mediocre predictor - what next?
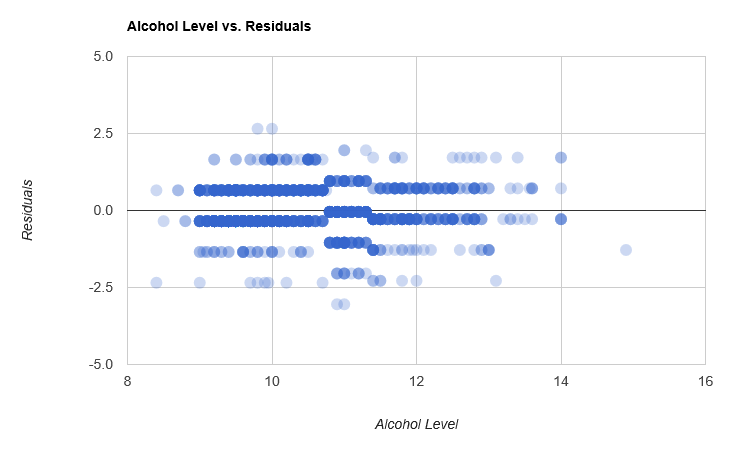
The only thing we considered so far was the overall average error across the sample. Perhaps looking in more detail at the prediction errors could prove useful. Let’s dig into the residuals, that is, the difference between our predictions and the correct value:
redSample
|> Seq.map (fun (obs,lbl) -> ``Alcohol Level`` obs, lbl - (obs |> bestStump))
|> Chart.Scatter
|> Chart.WithOptions options
|> Chart.WithTitle "Residuals vs. Quality"
|> Chart.WithXTitle "Residuals"
|> Chart.WithYTitle "Quality"
|> Chart.Show
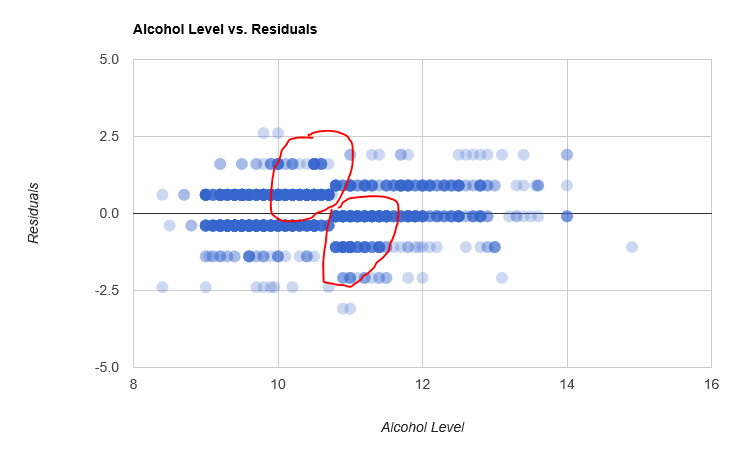
Overall, the errors are distributed somewhat evenly around 0.0; however, there is a bit of a visible pattern, marked in red on the chart. We seem to over-shoot in the region immediately on the left of the threshold, and under-shoot on the right. How about trying to fit a stump on the residuals, to capture effects our initial crude stump didn’t pick up?
let residualsSample =
redSample
|> Seq.map (fun (obs,lbl) -> obs, lbl - (obs |> bestStump))
let residualsStump =
alcoholSplits
|> List.map (learnStump residualsSample ``Alcohol Level``)
|> List.minBy (sumOfSquares redSample)
We can now combine our 2 stumps into one model, and evaluate it:
let combined = fun obs -> bestStump obs + residualsStump obs
sumOfSquares redSample combined
val combined : obs:Observation -> Label
val it : float = 850.3408387
The aggregate error went down from 864.43 to 850.34. We combined together 2 mediocre models, and got a clear improvement out of it. Let’s plot out what our combined model does:
redSample
|> Seq.map (fun (obs,value) -> (``Alcohol Level`` obs, obs |> combined))
|> Seq.sortBy fst
|> Chart.Line
|> Chart.WithTitle "Alcohol Level vs. Quality"
|> Chart.WithXTitle "Alcohol Level"
|> Chart.WithYTitle "Quality"
|> Chart.Show
Plotting the residuals now produces the following chart:
The overall error is better, but there are still potential patterns to exploit. What we could do at that point is repeat the procedure, and fit another stump on the new residuals to decrease the error further.
Iteratively adding stumps
Rather than manually create another stump, we can generalize the idea along these lines:
- Given a
Predictor, - Compute the residuals, the error between the
Predictorforecast and the correct value, - Find the Stump that matches most closely the residuals,
- Create a new
Predictor, by combining the current one with the new stump, - Repeat
In other words, at each step, we look at the errors from our current model, fit a new model to the residuals to reduce our error, combine them together, and repeat the procedure until we decide it’s enough.
Let’s implement this, using recursion, and stopping after a given number of adjustments:
let learn (sample:Example seq) (feature:Feature) (depth:int) =
let splits = evenSplits sample feature 10
let rec next iterationsLeft predictor =
// we have reached depth 0: we are done
if iterationsLeft = 0
then predictor
else
// compute new residuals
let newSample =
sample
|> Seq.map (fun (obs,y) -> obs, y - predictor obs)
// learn possible stumps against residuals,
// and pick the one with smallest error
let newStump =
splits
|> Seq.map (learnStump newSample feature)
|> Seq.minBy (sumOfSquares newSample)
// create new predictor
let newPredictor = fun obs -> predictor obs + newStump obs
// ... and keep going
next (iterationsLeft - 1) newPredictor
// initialize with a predictor that
// predicts the average sample value
let baseValue = sample |> Seq.map snd |> Seq.average
let basePredictor = fun (obs:Observation) -> baseValue
next depth basePredictor
We start with a Predictor that simply returns the average quality across the sample, and iteratively follow the approach previously outlined, until we reach our pre-defined number of iterations.
How well does it work? Let’s try it out:
let model = learn redSample ``Alcohol Level`` 10
sumOfSquares redSample model
val it : float = 811.4601191
Another clear improvement, from 850.34 to 811.46. How does our model look like now?
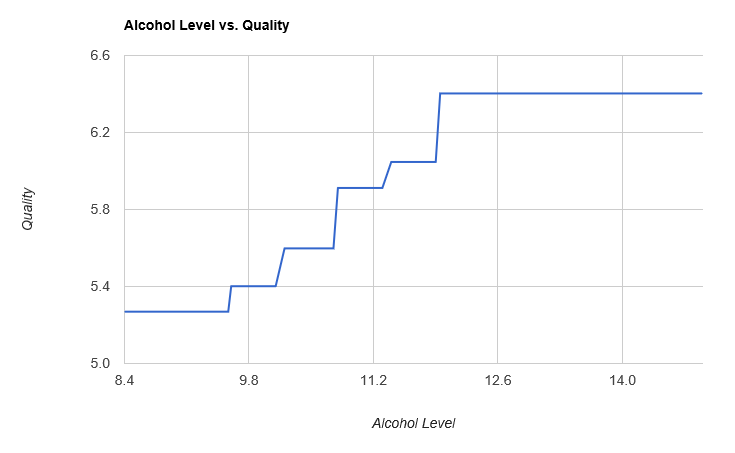
By combining simple stumps, our model is starting to look like a staircase, progressively approximating a curve. Let’s take a quick look at how our aggregate error evolves, as depth increases:
[ 1 .. 15 ]
|> Seq.map (fun depth -> depth, learn redSample ``Alcohol Level`` depth)
|> Seq.map (fun (depth,model) -> depth, sumOfSquares redSample model)
|> Chart.Column
|> Chart.Show
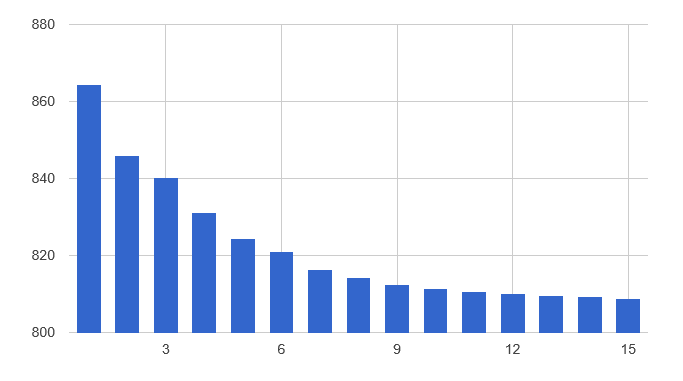
At each step, adding a stump decreases the overall error, with improvements slowing down progressively as we go deeper.
Conclusion
We used an extremely primitive base model (stumps) to create predictions. Each stump is a simple gate, predicting one value if the input is above a given threshold, and another otherwise. Yet, by combining these crude stumps, we managed to put in place an algorithm that becomes progressively better and better, generating a curve that matches the desired output more closely after each iteration.
Can we do better than that? Yes we can!
Currently, our learn function is relying on a single feature at a time; we are using only Alcohol Level, ignoring all the potential information present in Volatile Acidity, or the other 9 measurements we have available. Instead of learning on one feature only, we could already pick the best stump across multiple features.
Furthermore, there is nothing in the core learn algorithm that constrains us to use a stump. Instead of restricting ourselves to a stump, we could also use more complex models to match the residuals. In our next installments, we will look into learning trees instead of stumps, which will allow us to create Predictors using more that a single Feature at a time.
In the process, we will also revisit the question of how to combine models as we iterate. Our current approach is to simply stack our predictors together: fun obs -> predictor obs + newStump obs. However, this might not be the best combination available - we will look into that.